 gitsilence 的个人博客
gitsilence 的个人博客
Coding...
目录
判断文件的类型
判断文件的类型
前言
当我们写文件上传的时候,需要对上传的文件进行鉴别,防止黑客上传恶意脚本。
以往的方式都是通过文件的后缀名判断的,这样是不安全的。
用户通常可以将恶意文件伪装成合法后缀的文件,进行上传。
如今网上盛行的影视站,观看的流畅度和以往的差别很大
有些图床就是通过判断文件的后缀进行鉴别 是否是图片
还有限制文件的大小
其实 可以将电影 切片成一段一段的,将这些一段段的文件后缀改成图片的形式
然后批量上传到图床,然后将这些分片链接存储到m3u8文件中。
内容
通常在Web系统中,上传文件时都需要做文件的类型校验,大致有如下几种方法:
- 通过后缀名,如exe,jpg,bmp,rar,zip来判断。
- 通过读取文件,获取文件的Content-type来判断。
- 通过读取文件流,根据文件流中特定的一些字节标识来区分不同类型的文件。
- 若是图片,则通过缩放来判断,可以缩放的为图片,不可以的则不是。
然而,在安全性较高的业务场景中,1、2两种方法的校验会被轻易绕过。
读取文件头信息的方式较安全,并有16进制转换等操作,性能稍差,但能满足一定条件下对安全的要求,所以建议使用。
但是文件头的信息也可以伪造,对于图片可以采用缩放或者获取图片宽高的方法 避免伪造头信息。
使用vim 查看文件的头信息。
vim 2.jpg
执行如下 命令 并回车。
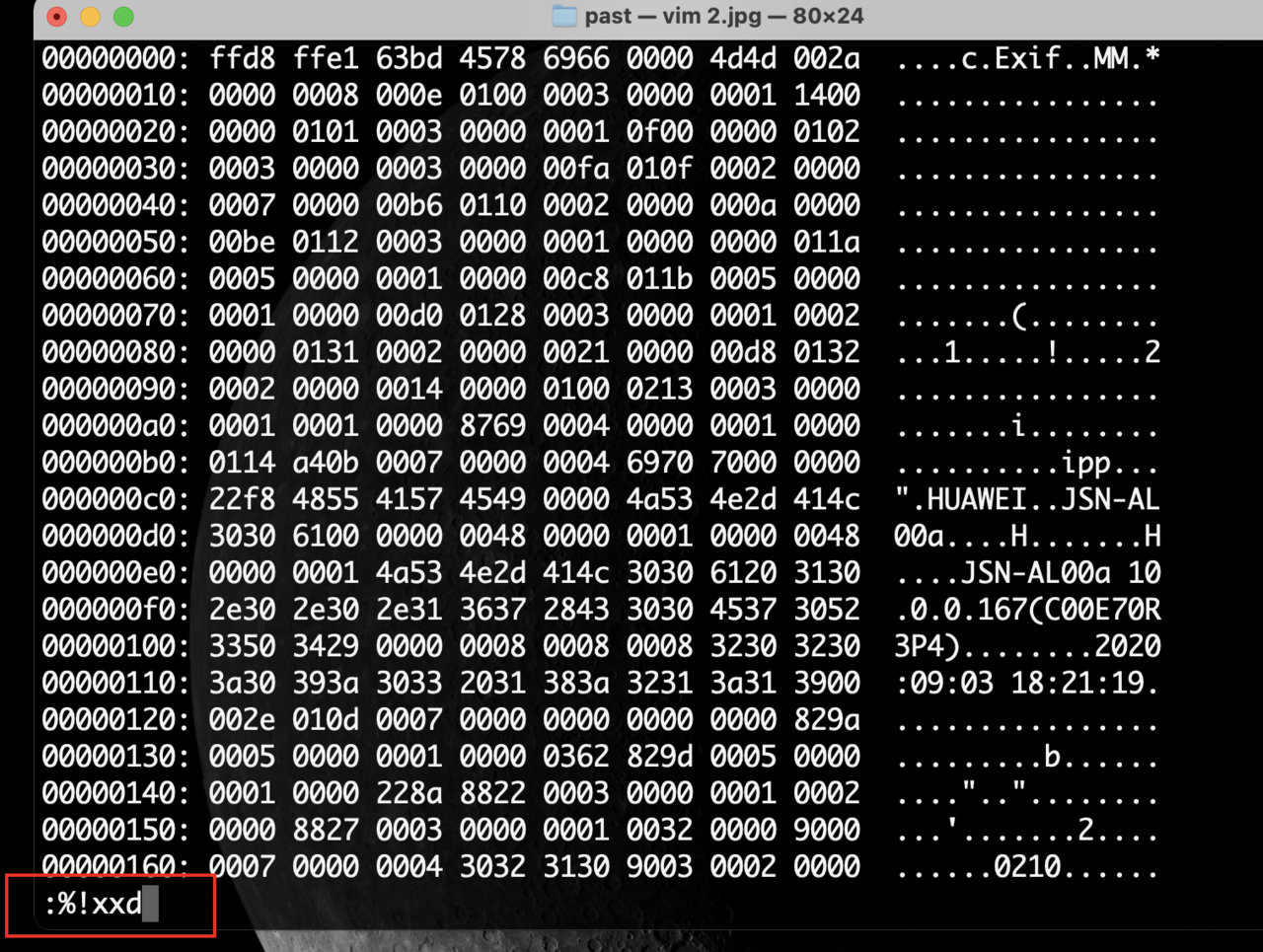
第一行 ffd8ffe1 就是文件头,一个十六进制数 占二进制 的 4位,等于一共是32位。
我们读取文件的时候,只读取4个字节就可以了。
@Test
public void fileType () {
FileInputStream inputStream = null;
try {
// 以字节 为单位 读取
inputStream = new FileInputStream(PIC_PATH);
// 读取4个字节,也就是32位
byte[] bytes = new byte[4];
inputStream.read(bytes);
for (int i = 0; i < bytes.length; i++) {
System.out.println(bytes[i]);
}
String s = bytesToHex(bytes);
System.out.println(s);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
性能和安全二者不可兼得,安全的同时付出了读取文件的代价。建议可采用后缀名与读取文件的方式结合校验。