 gitsilence 的个人博客
gitsilence 的个人博客
Coding...
Elasticsearch入门学习(二)

Elasticsearch入门学习(二)
文档的基本CRUD与批量操作
注意 下面 的users 是一个索引,类似于一张表
Create 一个文档
- 支持自动生成文档Id和指定文档Id两种方式
- 通过调用 “ post /users/_doc ”
- 系统会自动生成document Id
- 使用Http PUT user/_create/1创建时,URI中显示指定的 _create ,此时如果该id的文档已经存在,操作失败。
创建一个文档
使用post方式
# create document 自动生成 _id POST users/_doc { "user": "Jack", "post_date": "2020-10-11T21:18:55", "message": "trying out kibana" }{ "_index" : "users", "_type" : "_doc", "_id" : "z7jQF3UBdW2iN5NVuq-w", // id是系统自动帮我们生成的 "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 }使用put
# create document 指定id。如果id已经存在,报错 # 这里的op_type 操作类型,即为create,还可以为index PUT users/_doc/1?op_type=create # 等同于 PUT users/_create/1 { "user": "Mike ~ ~", "post_date": "2020-10-11T21:22:24", "message": "trying out Elasticsearch" }{ "_index" : "users", "_type" : "_doc", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 }当再次执行 这个put请求,就会报错
{ "error": { "root_cause": [ { "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, document already exists (current version [1])", "index_uuid": "P4KITo6zS_mkci8tDNl7Tg", "shard": "0", "index": "users" } ], "type": "version_conflict_engine_exception", // 由于版本冲突 "reason": "[1]: version conflict, document already exists (current version [1])", "index_uuid": "P4KITo6zS_mkci8tDNl7Tg", "shard": "0", "index": "users" }, "status": 409 }
Get 一个文档
- 找到文档,返回Http 200
- 文档元信息
- _index/ _type/
- 版本信息,同一个Id的文档,即使被删除,Version号也会不断增加
- _source 中默认包含了文档的所有原始信息
- 文档元信息
- 找不到文档,返回HTTP 404
GET获取
GET users/_doc/1{ "_index" : "users", // 代表 文档 所处的 索引 "_type" : "_doc", // 它的类型 是一个 文档 "_id" : "1", "_version" : 1, // version代表 它已经进行了1次改动了。 "_seq_no" : 1, "_primary_term" : 1, "found" : true, // source 表示 文档所有的原始信息 "_source" : { "user" : "Mike ~ ~", "post_date" : "2020-10-11T21:22:24", "message" : "trying out Elasticsearch" } }
Index 文档
- Index 和 create 不一样的地方:如果文档不存在,就索引新的文档。否则现有文档会被删除,新的文档被索引。版本信息 +1
我们继续新增数据,并且使用index方式,使用已经存在的id 1.
-
获取id为1的现在的值
{ "_index" : "users", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 1, "_primary_term" : 1, "found" : true, "_source" : { "user" : "Mike ~ ~", "post_date" : "2020-10-11T21:22:24", "message" : "trying out Elasticsearch" } } -
执行index方式
PUT users/_doc/1 { "msg": "I am using index !!!" }{ "_index" : "users", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 1 } -
查询id为1 现在的值
{ "_index" : "users", "_type" : "_doc", "_id" : "1", "_version" : 2, "_seq_no" : 3, "_primary_term" : 1, "found" : true, "_source" : { "msg" : "I am using index !!!" } }
这时候版本号 会 +1 .
Delete 一个文档
Delete users/_doc/2
{
"_index" : "users",
"_type" : "_doc",
"_id" : "2",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}
Update 文档
- Update 方法不会删除原来的文档,而是实现真正的数据更新
- Post 方法 / Payload需要包含在doc中
对id为1进行字段的增加。
POST users/_update/1
{
"doc": {
"post_date": "2020-10-11T21:45:15",
"message": "trying out Elasticsearch",
"status": "update success"
}
}
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"msg" : "I am using index !!!",
"post_date" : "2020-10-11T21:45:15",
"message" : "trying out Elasticsearch",
"status" : "update success"
}
}
Bulk API
- 支持一次API调用中,对不同的索引进行操作
- 支持四种类型操作
- index
- create
- update
- delete
- 可以在URI中指定index,也可以在请求的Payload中进行
- 操作中单条操作失败,并不会影响其他操作
- 返回结果包括了每一条操作执行的结果。
POST _bulk
{"index": {"_index": "test", "_id": "1"}}
{"filed1": "value1"}
{"delete": {"_index": "test", "_id": "2"}}
{"create": {"_index": "test2", "_id": "3"}}
{"field1": "value3"}
{"update": {"_id": "1", "_index": "test"}}
{"doc": {"field2": "value2"}}
{
"took" : 752,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"delete" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 404
}
},
{
"create" : {
"_index" : "test2",
"_type" : "_doc",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"update" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 200
}
}
]
}
mget - 批量读取
GET /_mget
{
"docs": [
{
"_index": "test",
"_id": "1"
},
{
"_index": "test",
"_id": "2"
}
]
}
{
"docs" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"filed1" : "value1",
"field2" : "value2"
}
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"found" : false
}
]
}
msearch - 批量查询
GET users/_msearch
{"index" : "test"}
{"query" : {"match_all" : {}}, "from" : 0, "size" : 10}
{"index" : "test", "search_type" : "dfs_query_then_fetch"}
{"query" : {"match_all" : {}}}
{}
{"query" : {"match_all" : {}}}
{"query" : {"match_all" : {}}}
{"search_type" : "dfs_query_then_fetch"}
{"query" : {"match_all" : {}}}
multi_match - 多字段搜索
GET twitter/_search
{
"query": {
"multi_match": {
"query": "朝阳",
"fields": [
"user",
"address^3",
"message"
],
"type": "best_fields"
}
}
}
不知道哪一个字段有这个关键词,可以使用上面的多字段搜索;multi_search 的type 为 best_fields 也就是说它搜索了3个字段。最终的分数 _score 是按照得分最高的那个字段的分数为准。
使用SQL查询、SQL转DSL
高版本的Elasticsearch 支持 SQL查询
GET /_sql?
{
"query": "select * from yx_device_event_info where appName = 'Telegram'"
}
也可以将我们的 sql 语句转成 dsl 语句
GET /_sql/translate
{
"query": "select * from yx_device_event_info where appName = 'Telegram'"
}
Profile API
profile API 是调试工具,它添加了有关执行的详细信息搜索请求中的每个组件。它为用户提供有关搜索的每个步骤的洞察了,请求执行并可以帮助确定某些请求为何缓慢。
GET twitter/_search
{
"profile": "true",
"query": {
"match": {
"city": "北京"
}
}
}
聚合操作 Aggregation
聚合框架有助于基于搜索查询提供聚合数据。它基于成为聚合的简单构建模块,可以组合以构建复杂的数据摘要。
- 存储桶 - Bucketing
构建存储桶的一系列聚合,其中每个存储桶与密钥合文档标准相关联。执行聚合时,将在上下文中的每个文档上评估所有存储桶条件,并且当条件匹配时,文档被视为落入相关存储桶。在聚合过程结束时,我们最终会得到一个桶列表 - 每个桶都有一组属于它的文档 - Mertric 指标
- Martrix
- Pipline
倒排索引
正排与倒排索引
图书和搜索引擎的类比
- 图书
- 正排索引 - 目录页
- 倒排索引 - 索引页
- 搜索引擎
- 正排索引 - 文档id到文档内容和单词的关联
- 倒排索引 - 单词到文档id的关系
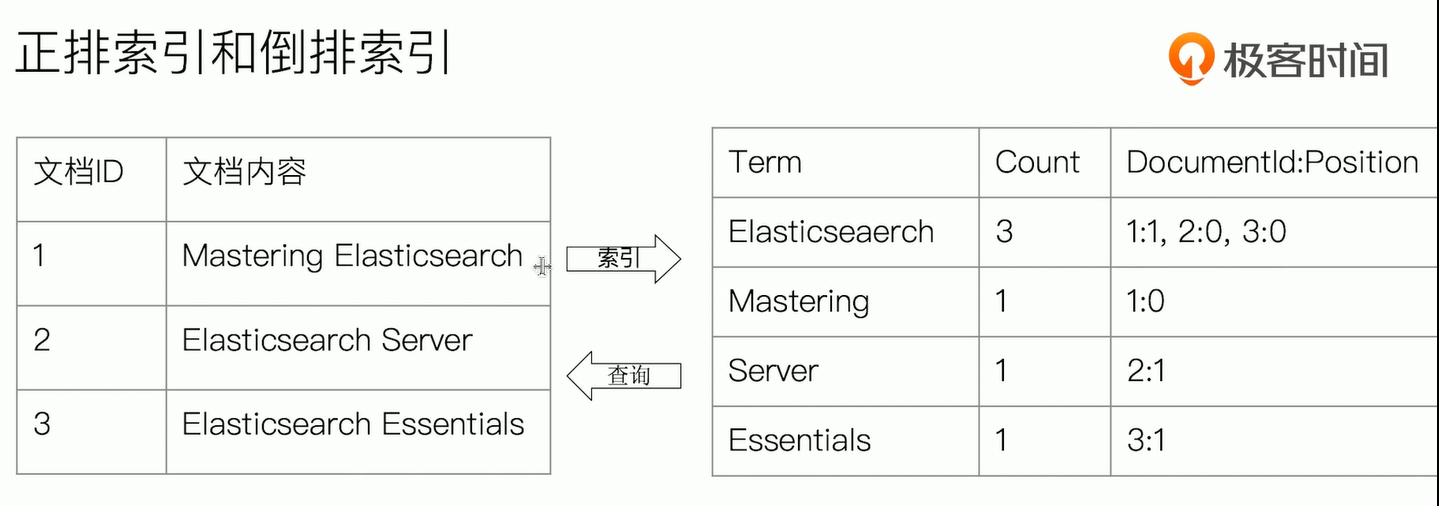
- 倒排索引包含两个部分
- 单词词典,记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般比较大,可以通过b+树或哈希链表法实现,以满足高性能的插入与查询
- 倒排列表 - 记录了单词对应的文档结合,由倒排索引项组成
- 倒排索引项
- 文档ID
- 词频TF - 该单词在文档中出现的次数,用于相关性评分
- 位置(position) - 单词在文档中分词的位置。用于语句搜索
- 偏移(offset) - 记录单词的开始结束位置,实现高亮显示
- 倒排索引项
- 单词词典,记录所有文档的单词,记录单词到倒排列表的关联关系
Elasticsearch的倒排索引
- Elasticsearch 的JSON文档中的每个字段,都有自己的倒排索引
- 在Mapping中可以指定对某些字段不做索引
- 优点:节省空间
- 缺点:字段无法被搜索
分词 - Analysis
Analysis 和 Analyzer
-
Anaylsis - 文本分析是把全文本转换一系列单词(term / token)的过程,也叫分词
-
Analysis是通过Analyzer来实现的
- 可使用Elasticsearch内置的分析器 / 或者按需定制化分析器
-
除了在数据写入时转换词条,匹配Query语句的时候也需要用相同的分析器对查询语句进行分析。
-
分词器是专门处理分词的组件,Analyzer由三部分组成
- Character Filters(针对原始文本处理,例如去除html)/ Tokenizer(按照规则切分为单词)/ Token Filter(将切分的单词进行加工,小写,删除stopwords,增加同义词)
Character Filters -> Tokenizer -> Token Filters
Elasticsearch的内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
过滤 停用词 默认是关闭的状态
- 按词切分
- 小写处理
# 输入一句话,对这句话进行分词处理 GET _analyze { "analyzer": "standard", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "<NUM>", "position" : 0 }, { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "<ALPHANUM>", "position" : 4 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "<ALPHANUM>", "position" : 5 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "<ALPHANUM>", "position" : 6 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "<ALPHANUM>", "position" : 8 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "<ALPHANUM>", "position" : 9 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "<ALPHANUM>", "position" : 10 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "<ALPHANUM>", "position" : 11 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "<ALPHANUM>", "position" : 12 } ] } - Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
- 按照非字母切分,非字母的都被去除
- 小写处理
GET _analyze { "analyzer": "simple", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }{ "tokens" : [ { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 0 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 1 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "word", "position" : 2 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "word", "position" : 3 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 4 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 5 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 6 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 7 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "word", "position" : 8 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "word", "position" : 9 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 10 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "word", "position" : 11 } ] } - Stop Analyzer - 小写处理,停用词过滤(the, a, is )
相比Simple Analyzer,多了stop filter
- 会把the,a,is,等修饰性词语去除
# 停用词过滤 GET _analyze { "analyzer": "stop", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }{ "tokens" : [ { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 0 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 1 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "word", "position" : 2 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "word", "position" : 3 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 4 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 5 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 6 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 7 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 10 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "word", "position" : 11 } ] } - Whitespace Analyzer - 按照空格切分,不转小写
按照空格切分
# 按照空格进行切分 GET _analyze { "analyzer": "whitespace", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "word", "position" : 0 }, { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 1 }, { "token" : "Quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 2 }, { "token" : "brown-foxes", "start_offset" : 16, "end_offset" : 27, "type" : "word", "position" : 3 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 4 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 5 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 6 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 7 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "word", "position" : 8 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "word", "position" : 9 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 10 }, { "token" : "evening.", "start_offset" : 62, "end_offset" : 70, "type" : "word", "position" : 11 } ] } - Keyword Analyzer - 不分词,直接将输入当作输出
不分词,直接将输入当一个term输出
# 不分词,直接输出 GET _analyze { "analyzer": "keyword", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }{ "tokens" : [ { "token" : "2 running Quick brown-foxes leap over lazy dogs in the summer evening.", "start_offset" : 0, "end_offset" : 70, "type" : "word", "position" : 0 } ] } - Pattern Analyzer - 正则表达式,默认\W+(非字母分割)
- 通过正则表达式进行分词
- 默认是\W+,非字母的符号进行分割。
# 正则表达式,默认是非字母分割 GET _analyze { "analyzer": "pattern", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "word", "position" : 0 }, { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 1 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 2 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "word", "position" : 3 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "word", "position" : 4 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 5 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 6 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 7 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 8 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "word", "position" : 9 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "word", "position" : 10 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 11 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "word", "position" : 12 } ] } - Language - 提供了30多种常见语言的分词器
支持不同国家的语言分词
# 不同国家语言分词 GET _analyze { "analyzer": "english", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "<NUM>", "position" : 0 }, { "token" : "run", "start_offset" : 2, "end_offset" : 9, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "fox", "start_offset" : 22, "end_offset" : 27, "type" : "<ALPHANUM>", "position" : 4 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "<ALPHANUM>", "position" : 5 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "<ALPHANUM>", "position" : 6 }, { "token" : "lazi", "start_offset" : 38, "end_offset" : 42, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "dog", "start_offset" : 43, "end_offset" : 47, "type" : "<ALPHANUM>", "position" : 8 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "<ALPHANUM>", "position" : 11 }, { "token" : "even", "start_offset" : 62, "end_offset" : 69, "type" : "<ALPHANUM>", "position" : 12 } ] }-
中文分词
分别进两个es中,安装插件
docker exec -it es72_02 sh
cd bin # es 安装插件 ./elasticsearch-plugin install analysis-icu安装完插件之后,重启一下
docker-compose stop docker-compose start
# 中文分词 POST _analyze { "analyzer": "icu_analyzer", "text": "他说的确实在理" }{ "tokens" : [ { "token" : "他", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "说的", "start_offset" : 1, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "确实", "start_offset" : 3, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "在", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "理", "start_offset" : 6, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 4 } ] } -
- Custom Analyzer 自定义分词器
更多的中文分词器
- iK
- 支持自定义词库,支持热更新分词字典
- https://github.com/medcl/elasticsearch-analysis-ik
- THULAC
- THU Lexucal Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
- https://github.com/microbun/elasticsearch-thulac-plugin
match、match_phrase、wildcard之间的区别。
-
match
-
match查询,会先对搜索词进行分词,比如“白雪公主和苹果”,会分成 白雪、公主、苹果,含有相关内容的字段,都会被检索出来。
-
wildcard
-
wildcard查询:是使用通配符进行查询,其中?代表任意一个字符,*代表任意一个或多个字符。
-
match_phrase
- match_phrase查询:match_phrase和slop一起用,能保证分词间的邻近关系,slop参数。match_phrase查询词条能够相隔多远时 仍然将文档视为匹配,默认是0,为0时,必须相邻才能被检索出来。
- 在对查询字段定义了分词器的情况下,会使用分词器对输入进行分词,然后返回满足下述两个条件的文档
- match_phrase 中的所有 term 都出现在待查询字段之中
- 待查询字段之中的所有 term 都必须和 match_phrase 具有相同的顺序
-
term
结构化字段查询,匹配一个值,且输入的值不会被分词器分词
开发者上手指南
https://elasticstack.blog.csdn.net/article/details/102728604
标题:Elasticsearch入门学习(二)
作者:MrNiebit
地址:https://blog.lacknb.cn/articles/2020/10/12/1602483097212.html
- Elasticsearch入门学习(二)
- 文档的基本CRUD与批量操作
- Create 一个文档
- Get 一个文档
- Index 文档
- Delete 一个文档
- Update 文档
- Bulk API
- mget - 批量读取
- msearch - 批量查询
- multi_match - 多字段搜索
- 使用SQL查询、SQL转DSL
- Profile API
- 聚合操作 Aggregation
- 倒排索引
- 正排与倒排索引
- Elasticsearch的倒排索引
- 分词 - Analysis
- Analysis 和 Analyzer
- Elasticsearch的内置分词器
- 更多的中文分词器
- match、match_phrase、wildcard之间的区别。
- 开发者上手指南