 gitsilence 的个人博客
gitsilence 的个人博客
Coding...
Elasticsearch入门学习(三)
官方文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/getting-started.html
以下内容摘抄自官方文档
基础知识
当一个节点被选举成为 主 节点时,它将负责管理集群范围内的所有变更;
例如 增加、删除索引,或者增加、删除节点等。而主节点并不需要涉及到文档级别的变更和搜索等操作
这里有个问题:当集群中只有一个节点时,这个节点是主节点,那么涉及到文档级别的变更和搜索等操作就不能进行了? 事实并非如此。
所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。
任何节点都可以成为主节点。
- 集群健康状态
- green: 所有的主分片 和 副本分片 都正常运行
- yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行
- red:有主分片没能正常运行
角色分离
参考地址:
https://www.cnblogs.com/sanduzxcvbnm/p/12850357.html
https://www.jianshu.com/p/6e7b970b1c1d
Master Node:主节点
Master eligible Node:有资格成为主节点的节点
Data Node:数据节点
Coordinating Node:协调节点
Ingest Node:ingest 节点
- Master Node:主节点,该节点不和应用创建连接,每个节点都保存了集群状态,master节点不占用磁盘IO和CPU,内存使用量一般。
- tribe Node:部落节点;tribe node 可以通过 tribe.* 相关参数的设置,它是一种特殊的 coordinate node(协调节点),它可以连接多个 es 集群上,然后对多个集群执行搜索等操作
部署后的成果:
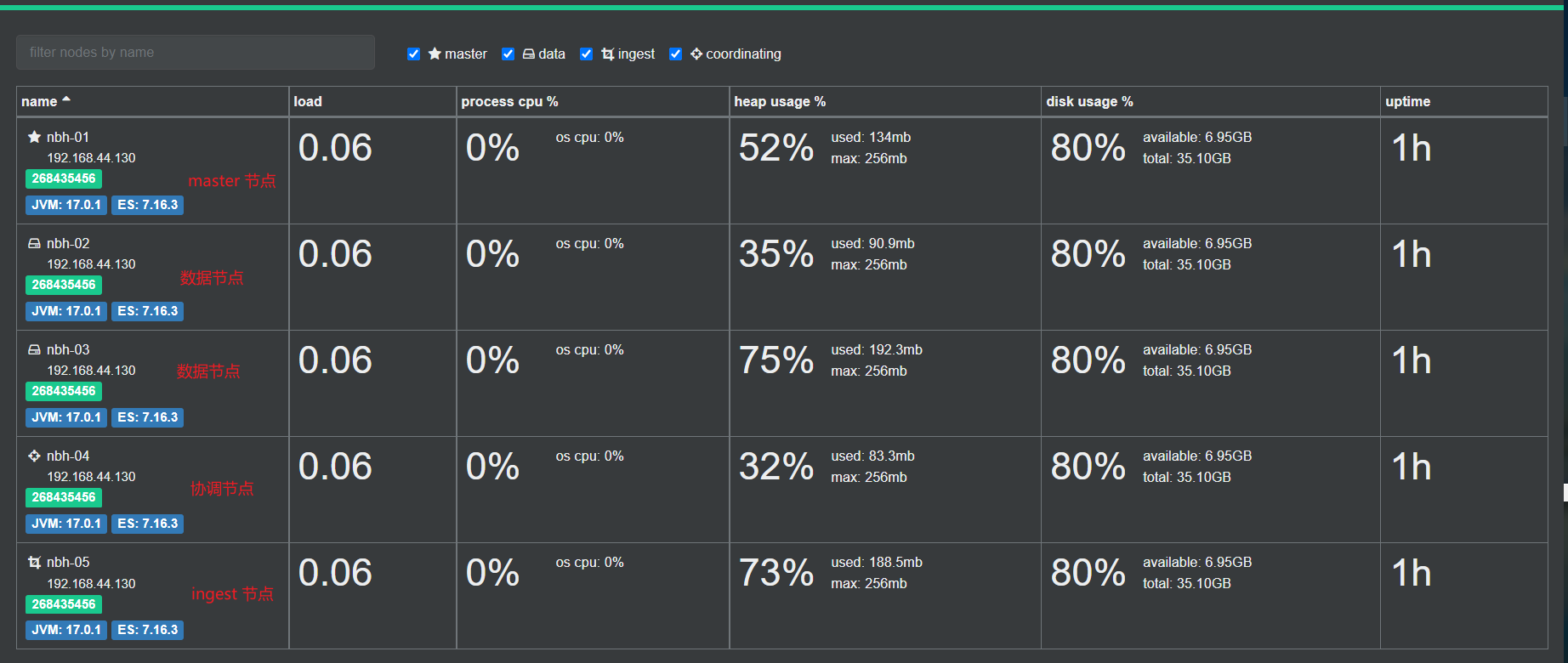
Master Eligible Node
合格节点,每个节点部署后不修改配置信息,默认就是一个 eligible 节点,该节点可以参加选主流程,成为Mastere节点。该节点也保存了集群节点的状态。eligible节点比Master节点更节省资源,因为它还未成为 Master 节点,只是有资格成功Master节点。
有资格成为 master 的节点;一个集群中只能有一个主节点,通过这些 eligible node 选举一个合适的节点作为当前集群中的主节点。
通过修改配置文件,设置 master eligible node 节点
node.master: true
node.data: false
node.ingest: false
通过minimum_master_nodes来避免脑裂问题
要预防数据的丢失,我们就必须设置discovery.zen.minimum_master_nodes参数为一个合理的值,这样的话,每个master-eligible node才知道至少需要多少个master-eligible node才能组成一个集群。
比如说,我们现在有一个集群,其中包含两个master-eligible nodes。然后一个网络故障发生了,这两个节点之间丢失了联络。每个节点都认为当前只有一个master-eligible node,就是它们自己。此时如果discovery.zen.minimum_master_nodes参数的默认值是1,那么每个node就可以让自己组成一个集群,选举自己为master node即可。结果就会导致出现了两个es集群,这就是脑裂现象。即使网络故障解决了,但是这两个master node是不可能重新组成一个集群了。除非某个master eligible node重启,然后自动加入另外一个集群,但是此时写入这个节点的数据就会彻底丢失。
那么如果现在我们有3个master-eligible node,同时将discovery.zen.minimum_master_nodes设置为2.如果网络故障发生了,此时一个网络分区有1个node,另外一个网络分区有2个node,只有一个node的那个网络分区,没法检测到足够数量的master-eligible node,那么此时它就不能选举一个master node出来组成一个新集群。但是有两个node的那个网络分区,它们会发现这里有足够数量的master-eligible node,那么就选举出一个新的master,然后组成一个集群。当网络故障解除之后,那个落单的node就会重新加入集群中。
discovery.zen.minimum_master_nodes,必须设置为master-eligible nodes的quorum,quorum的公式为:(master_eligible_nodes / 2) + 1。
换句话来说,如果有3个master-eligible nodes,那么那个参数就必须设置为(3 / 2) + 1 = 2,比如下面这样:
discovery.zen.minimum_master_nodes: 2
随着集群节点的上线和下限,这个参数都是要重新设置的,可以通过api来设置
PUT _cluster/settings
{
"transient": {
"discovery.zen.minimum_master_nodes": 2
}
}
此时将master node和data node分离的好处就出来了,一般如果单独规划一个master nodes的话,只要规划固定的3个node是master-eligible node就可以了,那么data node无论上线和下限多少个,都无所谓的。
作者:Shaw_Young
链接:https://www.jianshu.com/p/6e7b970b1c1d
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Data Node
数据节点,该节点和索引应用创建连接、接收索引请求,该节点真正存储数据,ES集群的性能取决于该节点的个数(每个节点最优配置的情况下),data节点会占用大量的CPU、IO和内存。
修改配置文件
node.master: false
node.ingest: false
node.data: true
Coordinating Node
协调节点,该节点和检索应用创建连接、接受检索请求,但其本身不负责存储数据,可当负责均衡节点,该节点不占用io、cpu和内存。
修改配置文件
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
search.remote.connect: false 是禁用跨集群查询,防止在进行集群之间查询时发生二次路由
Ingest Node
Ingest(进入、摄入)
ingest 节点可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
修改配置文件
node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
ES性能优化策略
文章地址:
- https://www.jianshu.com/p/4c57a246164c
- https://wenku.baidu.com/linkurl=bwD9mpebmQ28mqPj6Z0P1_A9bgFKnhIss8UrRA_Nsv7oTFuUEa9JgUdr9ynKc8OjWvd0pVLsp3tYZTFaNcxVt30EyFBCvkNflFGjMWcqsRq
- https://zhaoyanblog.com/archives/319.html
- https://www.jianshu.com/p/b4eda49583b5
1、elasticsearch 的配置文件中有两个参数:node.master 和 node.data。这两个参数搭配使用时,能够帮助提供服务器性能
node.master: false和node.data: true、node.ingest: false
该es节点只作为一个数据节点,只用于存储索引数据。使该 es节点 功能单一,只用于数据存储和数据查询,降低其资源消耗率node.master: true和node.data: false、node.ingest: fasle
该 es 节点 服务器只作为一个主节点,但不存储任何索引数据。该 es 服务器将使用自身空闲的资源,来协调各种创建所以请求或者查询请求,将这些请求合理分发到相关节点服务器上。(作为协调者)node.master: false和node.data: false、node.ingest: false
该 es 节点服务器 不会被选作 主节点(协调节点),也不会存储任何索引数据。该服务器主要用于查询负载均衡。在查询的时候,通常会涉及到从多个 node 服务器上查询数据,并请求分发到多个指定的node服务器,并对各个node服务器返回的结果进行一个汇总处理,最终返回客户端。(负载均衡器)
2、关闭 es 数据节点服务器 中的 http功能
- 针对 elasticsearch 集群中的所有数据节点,不用开启 http 服务。将其中的配置参数这样设置
http.enabled: false,同时也不要安装head、bigdesk、marvel 等监控插件,这样保证 data 节点服务器只需处理 创建、更新、删除、查询索引数据等操作 - http 功能可以在非数据节点服务器上开启,上述相关的监控插件也安装到这些服务器上,用于监控 elasticsearch 集群状态等数据信息
3、分片的数量
基于索引分片数=数据总量/单分片数
分片(Shard):一个索引会分成多个分片存储,分片数量在索引建立后不可更改, 推荐【分片数*副本数=集群数量】
ElasticSearch在创建索引数据时,最好指定相关的shards数量和replicas, 否则会使用服务器中的默认配置参数 shards=5,replicas=1。
因为这两个属性的设置直接影响集群中索引和搜索操作的执行。假设你有足够的机器来持有碎片和副本,那么可以按如下规则设置这两个值:
- 拥有更多的碎片可以提升索引执行能力,并允许通过机器分发一个大型的索引;
- 拥有更多的副本能够提升搜索执行能力以及集群能力。
对于一个索引来说,number_of_shards只能设置一次,而number_of_replicas可以使用索引更新设置API在任何时候被增加或者减少。
这两个配置参数在配置文件的配置如下:
index.number_of_shards: 5 number_of_replicas: 1
Elastic官方文档建议:一个Node中一个索引最好不要多于三个shards.配置total_shards_per_node参数,限制每个index每个节点最多分配多少个发片.
作者:jacksu在简书
链接:https://www.jianshu.com/p/b4eda49583b5
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
集群示例
数据节点:2 -> 2T
主节点: 3 -> 20G
协调节点:5 -> 20G
标题:Elasticsearch入门学习(三)
作者:gitsilence
地址:https://blog.lacknb.cn/articles/2021/11/07/1636299897869.html