 gitsilence 的个人博客
gitsilence 的个人博客
Coding...
SQL笔记
odps 的使用
odps的函数 可以参考oracle 对应的函数
函数
-
coalesce(a, b, c, d) 返回列表中第一个非NULL值,如果列表中所有的值都为NULL,则返回NUKKLL
-
insert into 和 insert overwrite 操作可以加个 select 查询的结果保存至目标中。二者区别是:
- insert into 直接向表或静态分区中插入数据,可以在insert语句中直接指定分区值,将数据插入指定的分区,。
- insert overwrite 先清空表中的原有数据,再向表中或静态分区中插入数据
-
窗口函数
https://blog.csdn.net/CSDNGYB/article/details/102486346
数据按照一定条件分成多组称为开窗,每个组称为一个窗口,partition by 部分用来指定开窗的列;
分区列的值相同的行,被视为在同一个窗口内,order by 用来指定数据在同一个窗口内如何排序
-- 例如 一张表,分成多个区,我要根据身份证查询每个区这些记录的最近创建时间;
select max(create_time) over (partition by id_card) mx_create_time from t_xxx -
partition by和group by的区别Oracle 环境下,如下操作
表结构:
-- auto-generated definition create table EMPLOYEE ( ID NUMBER(10) not null primary key, EMPNAME VARCHAR2(20), EMPSALARY VARCHAR2(10), EMPDEPARTMENT VARCHAR2(20) )
导入数据
insert into MY_TABLE (id, first_name, last_name, birth)
values (10001, 'Georgi', 'Facello', 'M'),
(10002, 'Bezalel', 'Simmel', 'F'),
(10003, 'Parto', 'Bamford', 'M'),
(10004, 'Chirstian', 'Koblick', 'M'),
(10005, 'Kyoichi', 'Maliniak', 'M'),
(10006, 'Anneke', 'Preusig', 'F'),
(10007, 'Tzvetan', 'Zielinski', 'F'),
(10008, 'Saniya', 'Kalloufi', 'M'),
(10009, 'Sumant', 'Peac', 'F'),
(10010, 'Duangkaew', 'Piveteau', 'F');
问题:计算每个部门的薪水总和 ?
两种方式
-
方式一
select EMPDEPARTMENT, sum(EMPSALARY) from EMPLOYEE group by EMPDEPARTMENT;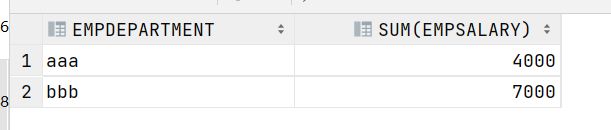
-
方式二
-- 使用开窗函数over,通过partition by 进行分组 select EMPSALARY, EMPDEPARTMENT, sum(EMPSALARY) over (partition by EMPDEPARTMENT) from EMPLOYEE ;
wordCount示例:https://help.aliyun.com/document_detail/27886.html
odps 客户端 console 常用命令
# 1、help; 查看帮助
# 2、list resources; 查询资源列表
# 3、drop resource xxx.jar; 删除指定资源
# 4、add jar D:\DeskTop\xx.jar; 添加指定资源,来自本地
对于我们通过 odps 客户端上传的资源,需要我们手动更新
到这里 查看已经上传的资源
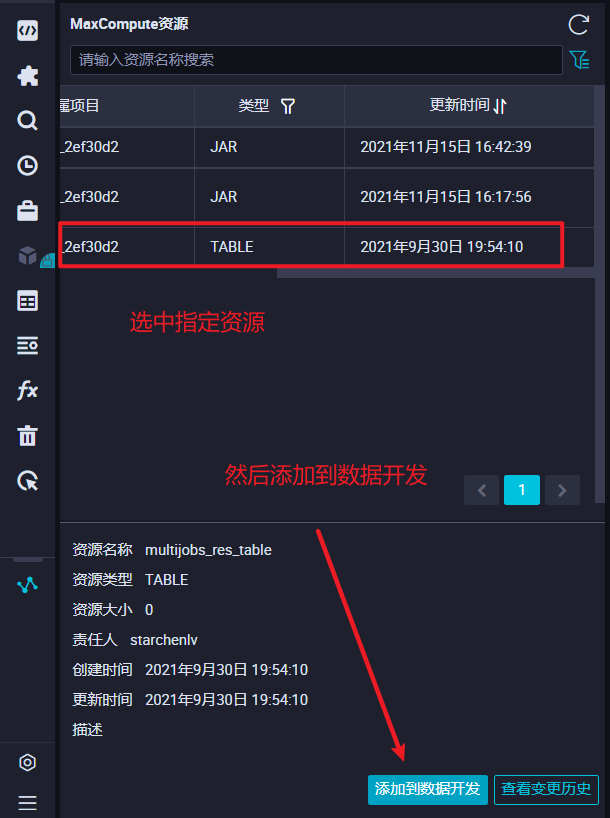
mr执行命令
--@resource_reference{"ph-odps-ext.jar"}
jar -resources ph-odps-ext.jar -classpath ph-odps-ext.jar com.xx.odps.mr.example.WordCount wc_in wc_out
clickhouse 常用的函数
-
extractAllGroupsHorizontal(field, '(regexp)')
目前只用了 select 关键字匹配 -
arrayDistinct([])
对数组里的元素去重 -
解析数组 json
-- 这里为数组的格式 with '[{"a": 1, "b": 2}, {"a": 5, "b": 66}]' as json_data -- ['{"a":1,"b":2}','{"a":5,"b":66}'] -- select JSONExtractArrayRaw(json_data) -- 转多行,将[]裂开多行 -- select arrayJoin(JSONExtractArrayRaw(json_data)); -- 获取 每个 json 串指定的属性 -- 1 -- 5 select visitParamExtractUInt(arrayJoin(JSONExtractArrayRaw(json_data)), 'a') -
当我们使用 replacingMergeTree 时,想要合并单个分区的相同数据,需要 op 表
optimize table table_name